
How to setup the Cheshire Cat to run a custom Large Language Model (LLM).
The Cheshire Cat offers two ways to setup a custom LLM, different from the
- using the Text Generation Inference service by Hugging Face;
- serving the LLM behind a custom REST server.
Option number 1 will be treated in a dedicated tutorial. In this post, we are focusing on the option number 2. The general idea of this solution is to create an endpoint under which you’ll perform the inference using you LLM. The Cheshire Cat will make a POST request such endpoint, sending a properly formatted request body and expecting a properly formatted JSON answer.
Please, note that the setup may vary according to the model and the inference framework you choose. This article tries to be as agnostic as possible, without making assumptions about the aforementioned choices and providing information about the Cheshire Cat’s general setup. Downloading and running the LLM at hand is up to you.
Custom LLM REST API
Here is how to setup and run a REST API server in Python to serve the LLM. For the purpose, we’ll be using FastAPI.
- First, you need to install a couple of dependencies. Hence, run:
pip install fastapi uvicorn- Now, you can start creating the server. Create a file named
main.pyand import the necessary modules:
from fastapi import FastAPI
from pydantic import BaseModelCode language: JavaScript (javascript)- Define the class to represent the request body the Cheshire Cat sends and create an instance of the FastAPI app:
class RequestBody(BaseModel):
text: str
auth_key: str | None = None
option: dict | None = None
app = FastAPI()
# Instantiate your LLM here, e.g.:
# llm = ...- Define the endpoint to serve the model. Please, note that the Cheshire Cat is always expecting a dictionary with a
textkey that stores the LLM answer as a response:
@app.post("/custom-llm/")
async def root(request_body: RequestBody):
# The incoming message sent by the Cheshire Cat
user_message = request_body.text
# Here you can perform inference using the LLM
# this part strongly depends on the framework you are using, e.g.
# answer = llm.predict(user_message)
return {"text": answer}Code language: PHP (php)- Run the following in your terminal to serve locally the app on
localhostand port 8000:
uvicorn main:app --host 0.0.0.0 --port 8000Code language: Bash (bash)- Before moving to the Cat GUI, you can test the app is running correctly in the Swagger, i.e. http:localhost:8000/docs:
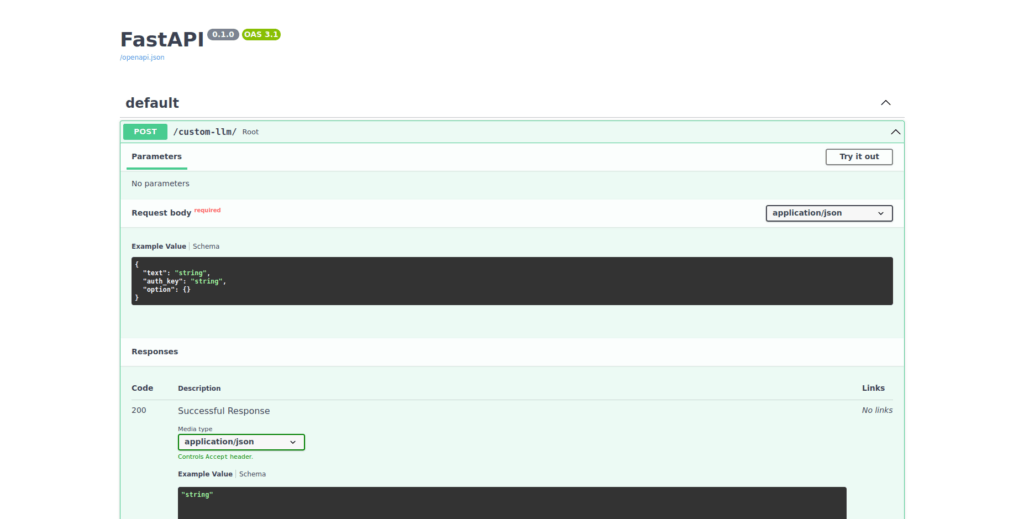
Custom LLM GUI setup
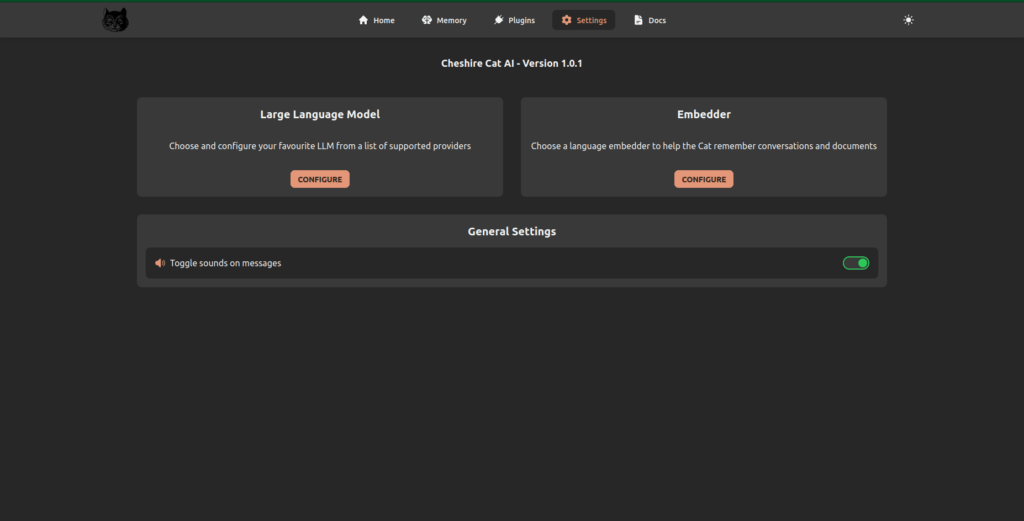
Once the server is running, you have to setup the LLM from the “Settings” page, like any other LLM.
- From your browser, navigate to the “Settings” page to configure a Large Language Model
- Choose Custom LLM from the dropdown menu and fill the parameters:
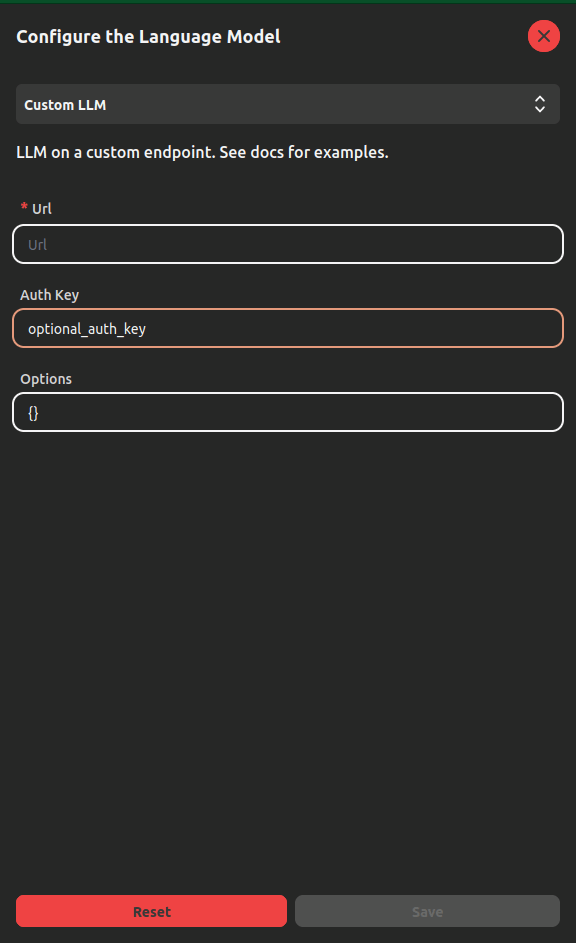
The parameters are: url, that is the mandatory address where the REST API is running; Auth Key, that is an optional key to authenticate the connection; Options, that is an optional parameter where you can pass a dictionary-like text that stores the language model parameters.
- Click on Save.
Please, note that the Cheshire Cat is running inside a Docker container. Thus, it has it’s own network bridge called docker0. Once you start the Cat’s container, your host machine (i.e. your computer) is assigned an IP address under the Docker network. Therefore, you should set the url parameter accordingly.
Let’s make an example: in the code above the url parameter should be
http://localhost:8000/custom-llm. However, you have to changelocalhostwith the IP address that Docker assigns to your machine. This depends on your Operating System, thus I invite you to explore further.
As anticipated, the configuration may vary according to your Operating System, the LLM and the inference framework you choose. Thus, this is not an in-depth guide with a practical example. Rather, this tutorial explains the general minimal setup to run a custom LLM with the Cheshire Cat. At this point, you are ready to test your custom LLM with your plugins!
Nicola Corbellini is a PostDoc Researcher at the InfoMus Lab, Casa Paganini, within the DIBRIS department of the University of Genoa. His research focuses on Social Signal Processing, with interests in Hybrid Intelligence and Multimodal Human-Computer Interaction.
Beyond academia, Nicola works as a software developer and has a keen interest in interactive generative visual and new media art.